
Die moderne Geschäftswelt ist so stark digitalisiert, dass fast jedes Unternehmen auf zuverlässige IT-Systeme angewiesen ist. Schon kurze Ausfallzeiten von Servern oder kritischen Anwendungen können zu hohen finanziellen Verlusten, frustrierten Kunden und einem massiven Vertrauensverlust führen.
Aus diesem Grund rückt der Begriff „High Availability“ (HA) immer stärker in den Fokus: IT-Architekturen müssen so ausfallsicher gestaltet sein, dass ein Service selbst dann weiterläuft, wenn einzelne Komponenten versagen.

Doch wie setzt du „hohe Verfügbarkeit“ in der Praxis um? Und welche Strategien helfen dir dabei, Ausfallzeiten zu minimieren oder komplett zu vermeiden? In diesem Artikel gehen wir tief ins Detail und beleuchten Konzepte, Methoden und Best Practices für hochverfügbare Serverumgebungen.
Was ist High Availability?
High Availability bezeichnet die Fähigkeit eines Systems, einen Dienst oder eine Anwendung über einen möglichst langen Zeitraum ohne Unterbrechung bereitzustellen. Dieser Zeitraum wird oft als Prozentzahl definiert – beispielsweise 99,99 % im Jahr. Diese Kennzahl, oft als „Vier Neunen“ bezeichnet, bedeutet, dass ein System nur wenige Minuten im Jahr ungeplant ausfallen darf. Manche Branchen, wie die Finanzwelt oder der Gesundheitssektor, fordern noch höhere Verfügbarkeitswerte, da hier bereits Sekundenbruchteile enorme Konsequenzen haben.
HA geht jedoch weit über die bloße Messung von Ausfallzeiten hinaus. Es ist ein ganzheitlicher Ansatz, der alle Schichten deiner IT umfasst – von der Hardware und den Netzwerkverbindungen bis hin zur Software und den organisatorischen Prozessen. Dein Ziel ist es, Störungen entweder komplett zu vermeiden oder die Zeitspanne bis zur Wiederherstellung (MTTR - Mean Time To Recovery) auf ein Minimum zu reduzieren. Hierfür brauchst du ein durchdachtes Zusammenspiel aus Redundanz, Clustering, Monitoring und Failover-Mechanismen.
Kennzahlen und SLA-Anforderungen
Um „hohe Verfügbarkeit“ messbar zu machen und vertraglich zu fixieren, arbeiten viele Unternehmen mit Service Level Agreements (SLAs). Ein SLA legt fest, welche Uptime du als Betreiber garantieren musst und welche maximalen Ausfallzeiten (Downtime) toleriert werden.
Dabei gilt: Je höher die Anzahl der „Neunen“, desto exponentiell steigen Aufwand und Kosten für Redundanz und Failover-Technik.
| Verfügbarkeit | Bezeichnung | Ausfallzeit pro Jahr | Ausfallzeit pro Monat | Typischer Anwendungsfall |
| 99,0 % | Zwei Neunen | ~ 3 Tage, 15 Std. | ~ 7 Std. 18 Min. | Interne Batch-Jobs, nicht-kritische Testsysteme. |
| 99,5 % | - | ~ 1 Tag, 19 Std. | ~ 3 Std. 39 Min. | Standard-Webseiten, einfache File-Server. |
| 99,9 % | Drei Neunen | ~ 8 Std. 45 Min. | ~ 43 Min. | Standard für KMU-Server, E-Mail-Dienste. |
| 99,95 % | - | ~ 4 Std. 22 Min. | ~ 21 Min. | Wichtige Business-Applikationen (ERP, CRM). |
| 99,99 % | Vier Neunen | ~ 52 Min. 35 Sek. | ~ 4 Min. | E-Commerce, Enterprise-Lösungen, Rechenzentren. |
| 99,999 % | Fünf Neunen | ~ 5 Min. 15 Sek. | ~ 26 Sek. | Banken, Telekommunikation, Medizintechnik. |
| 99,9999 % | Sechs Neunen | ~ 31,5 Sek. | ~ 2,6 Sek. | Militärische Systeme, Luftfahrt (Safety Critical). |
Wichtig für deine Planung: Es kann extrem schwierig sein, das letzte Quäntchen an Uptime zu garantieren, da praktisch jede technische Komponente, vom RAID-Controller bis zum Klimagerät, irgendwann ausfallen kann. Du musst dir deshalb gut überlegen, welche Services wirklich „Fünf Neunen“ benötigen und wo „Drei Neunen“ (und damit fast 9 Stunden Wartungsfenster pro Jahr) völlig ausreichen.
Redundanz: Der Schlüssel zur Ausfallsicherheit
Ein Grundpfeiler für hohe Verfügbarkeit ist die Redundanz: Das Vorhalten mehrerer baugleicher Ressourcen, damit beim Ausfall einer Komponente sofort eine andere übernimmt (N+1 oder 2N Redundanz).
- Server-Hardware: Statt nur einen physischen Host zu nutzen, hältst du mindestens zwei identische Maschinen vor.
- Netzwerkkomponenten: Router, Switches oder Firewalls werden im HA-Verbund (z.B. VRRP, HSRP) eingesetzt.
- Stromversorgung: USVs und redundante Netzteile sind Pflicht. Wichtig: Schließe redundante Netzteile an getrennte Stromkreise (A/B Feed) an, um den Single Point of Failure zu vermeiden.
- Speicherlösungen: RAID-Konfigurationen oder verteilte Speichersysteme (z.B. Ceph, vSAN) verhindern Datenverlust bei Plattenausfällen.

Cluster-Lösungen für hohe Verfügbarkeit
Cluster-Technologien bilden das technologische Rückgrat der meisten hochverfügbaren Umgebungen. Das Grundprinzip ist die Orchestrierung: Mehrere eigenständige Server (Nodes) werden logisch so gekoppelt, dass sie nach außen hin – also für den Client oder die Anwendung – wie ein einziges, robustes System (Single System Image) agieren. Damit dies funktioniert, benötigen Cluster in der Regel eine Heartbeat-Verbindung zur gegenseitigen Überwachung und eine Shared Storage oder synchronisierte Datenbasis, auf die alle Knoten zugreifen können.
Der Zugriff für die Clients erfolgt dabei meist über eine vIP (Virtual IP). Diese IP-Adresse ist nicht fest an einen physischen Server gebunden, sondern „schwebt“ und wird vom Cluster-Manager dynamisch dem Knoten zugewiesen, der gerade den Dienst bereitstellt.
In der Praxis unterscheiden wir vor allem zwei Betriebsmodi, die jeweils spezifische Vor- und Nachteile für deine Architektur mitbringen:
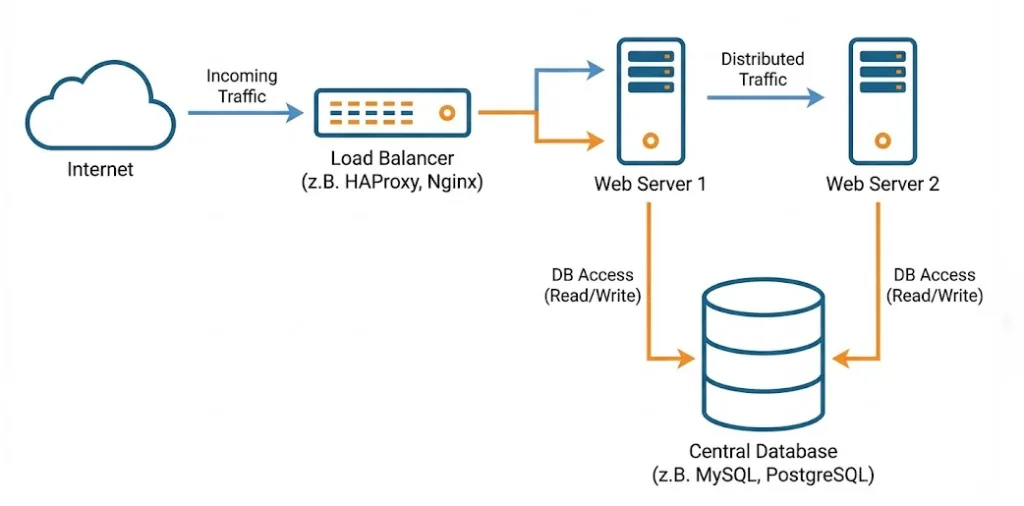
1. Active-Active-Cluster (Load Balancing & High Availability)
In diesem Szenario sind alle Knoten gleichzeitig aktiv und verarbeiten Anfragen. Ein vorgelagerter Load Balancer (z. B. HAProxy, NGINX oder Hardware-Appliances wie F5) verteilt den Traffic auf die verfügbaren Knoten.
- Funktionsweise: Alle Server laufen unter Last. Fällt Node A aus, erkennt der Load Balancer dies und leitet den Traffic sofort auf Node B und C um.
- Der Vorteil: Du nutzt deine Hardware effizient aus. Es gibt keine „tote“ Ressource, die nur Strom verbraucht und auf einen Fehler wartet. Zudem kannst du Wartungsarbeiten (Rolling Updates) durchführen, indem du einzelne Knoten nacheinander aus dem Load Balancer nimmst, patchst und wieder einfügst.
- Die Falle (Capacity Planning): Ein häufiger Fehler ist die Fehlkalkulation der Restkapazität. Wenn du zwei Server hast, die beide zu 80 % ausgelastet sind, und einer fällt aus, muss der verbleibende Server plötzlich 160 % der Last tragen – was zum sofortigen Totalabsturz führt (Kaskadeneffekt). In einem 2-Node Active-Active-Cluster darfst du jeden Knoten also maximal zu 50 % auslasten, um im Failover-Fall sicher zu sein.
- Einsatzgebiet: Ideal für stateless (zustandslose) Dienste wie Webserver, Applikationsserver oder Microservices, da hier keine komplexen Sperr-Mechanismen für gleichzeitige Schreibzugriffe auf dieselbe Datenbank nötig sind.
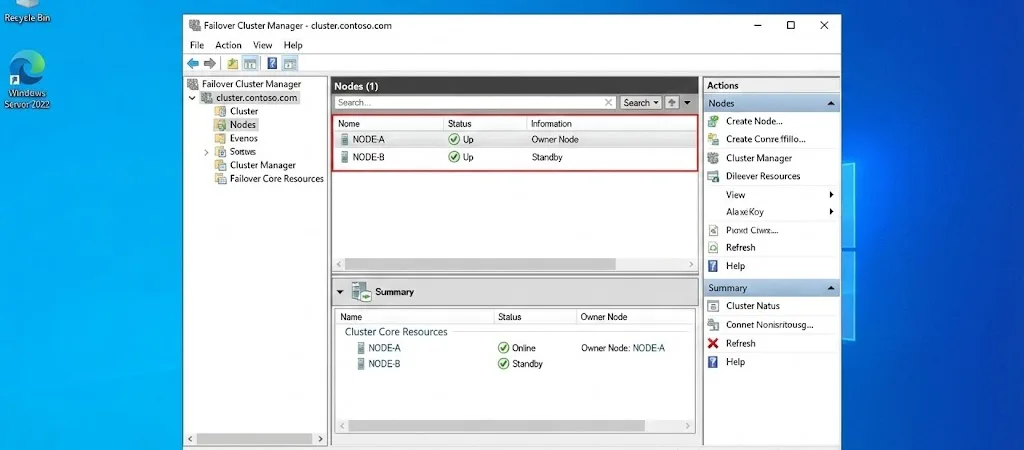
2. Active-Passive-Cluster (Failover-Cluster)
Hier übernimmt ein primärer Knoten (Master/Primary) die volle Last, während ein oder mehrere sekundäre Knoten (Slave/Secondary/Standby) im Hintergrund warten und den Zustand des Primärknotens überwachen.
- Funktionsweise: Der passive Knoten synchronisiert sich in der Regel fortlaufend mit dem aktiven (Datenreplikation). Fällt der aktive Knoten aus („Heartbeat Loss“), schwenkt die Cluster-Resource-Manager-Software (z. B. Pacemaker unter Linux oder Windows Server Failover Clustering) die Dienste und die virtuelle IP auf den passiven Knoten um.
- Der Vorteil: Diese Architektur ist oft einfacher zu verwalten, insbesondere bei stateful (zustandsbehafteten) Anwendungen. Da immer nur ein Knoten schreibt, vermeidest du Probleme mit Datenkonsistenz (Data Corruption) und komplexen File-Locking-Mechanismen. Die Fehlersuche ist oft linearer.
- Der Nachteil: Du bezahlst für Hardware, die 99 % der Zeit nichts tut. Zudem gibt es beim Umschalten (Failover) fast immer eine kurze Unterbrechung (Downtime im Sekundenbereich), bis der Standby-Knoten die Dienste vollständig hochgefahren und die Dateisysteme übernommen hat.
- Einsatzgebiet: Der Klassiker für Datenbanken (z. B. SQL Server Failover Cluster, PostgreSQL mit Patroni) oder zentrale Fileserver, wo Datenintegrität absolute Priorität vor maximaler Performance-Skalierung hat.
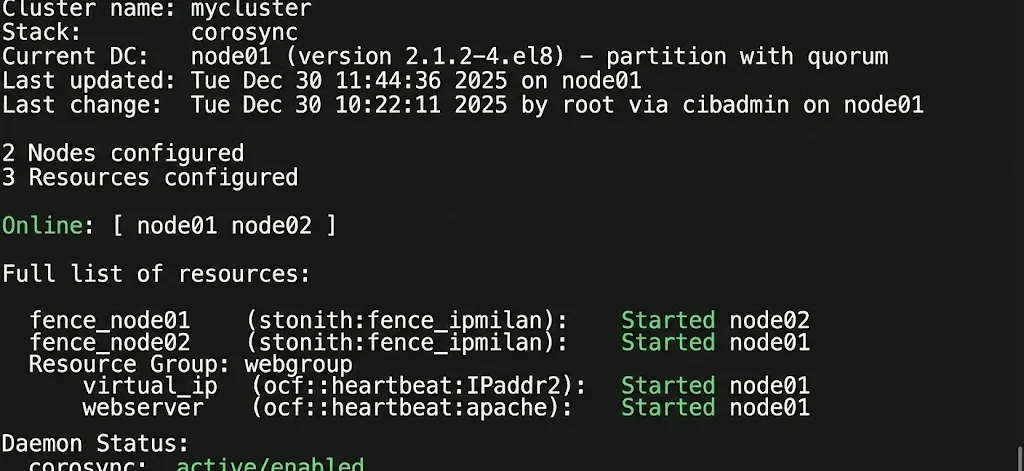
Failover-Mechanismen: Wechsel bei Ausfall
Failover ist weit mehr als nur ein „Umschalten“; es ist ein hochkomplexer Entscheidungsprozess, der binnen Sekundenbruchteilen ablaufen muss. Wenn der primäre Knoten versagt, muss das System autonom entscheiden, ob es sich um einen echten Ausfall oder nur um ein kurzes Netzwerkproblem handelt. Damit dieser „Staffellauf“ ohne Datenverlust gelingt, setzen HA-Cluster auf mehrstufige Sicherheitsmechanismen:
- Heartbeats & Cluster Communication: Die Knoten überwachen sich gegenseitig durch regelmäßige Statussignale („Heartbeats“). Technisch wird dies oft über Corosync oder proprietäre Cluster-Interconnects gelöst.
- Best Practice: Um „False Positives“ (fälschliche Ausfallerkennung bei Netzwerklast) zu vermeiden, solltest du Heartbeats immer über dedizierte Netzwerk-Interfaces oder VLANs routen (Redundant Ring Protocol), getrennt vom regulären Datenverkehr.
- Best Practice: Um „False Positives“ (fälschliche Ausfallerkennung bei Netzwerklast) zu vermeiden, solltest du Heartbeats immer über dedizierte Netzwerk-Interfaces oder VLANs routen (Redundant Ring Protocol), getrennt vom regulären Datenverkehr.
- Split-Brain-Vermeidung & Quorum: Das Worst-Case-Szenario in jedem Cluster ist das „Split-Brain“. Wenn die Verbindung (Interconnect) zwischen den Knoten abreißt, laufen beide Server weiter, sehen sich aber gegenseitig nicht mehr. Wenn nun beide versuchen, gleichzeitig die „Master“-Rolle zu übernehmen und auf das Shared Storage zu schreiben, droht massive Datenkorruption.
- Die Lösung: Ein Quorum-Mechanismus (Abstimmungsverfahren). Ein Cluster ist nur dann handlungsfähig, wenn er die Mehrheit der Stimmen (Votes) besitzt (Formel:
(n/2) + 1). Bei zwei Knoten benötigt man einen externen Schiedsrichter, den sogenannten Tie-Breaker oder Witness (oft ein kleiner, externer File-Share oder eine virtuelle Instanz), der die entscheidende Stimme vergibt.
- Die Lösung: Ein Quorum-Mechanismus (Abstimmungsverfahren). Ein Cluster ist nur dann handlungsfähig, wenn er die Mehrheit der Stimmen (Votes) besitzt (Formel:
- Fencing / STONITH: Wenn ein Knoten nicht mehr reagiert, darf der Rest des Clusters nicht einfach annehmen, dass er aus ist. Er könnte noch in einem „Zombie-Status“ hängen und sporadisch Daten schreiben. Hier greift STONITH („Shoot The Other Node In The Head“), auch als Fencing bekannt.
- Die Technik: Der Cluster-Manager verbindet sich direkt mit der Management-Karte des Servers (z. B. iDRAC, iLO, IPMI) oder einer schaltbaren Steckdosenleiste (switched PDU). Der fehlerhafte Knoten wird physisch stromlos geschaltet (Hard Fencing). Erst wenn die Bestätigung vorliegt („Node is down“), übernimmt der Standby-Knoten die Ressourcen und die IP-Adresse. Das klingt radikal, ist aber der einzige Weg, 100%ige Datenintegrität zu garantieren.
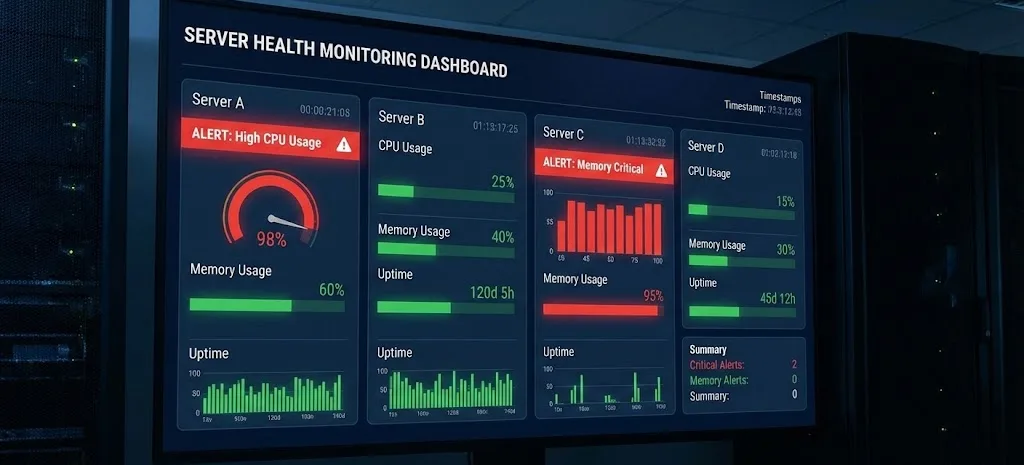
Monitoring und proaktive Wartung
„Ohne Monitoring fliegst du blind“ ist im HA-Umfeld keine Floskel, sondern ein Risiko für den Geschäftsbetrieb. Du musst unterscheiden zwischen dem reinen „Up/Down“-Status (Ping) und dem tatsächlichen Gesundheitszustand der Applikation („Application Health“). Tools wie Zabbix, Prometheus, Checkmk oder Datadog sind hier Industriestandards.
Ein modernes Monitoring-Konzept ruht auf drei Säulen:
- Ganzheitliche Metriken (Observability): Es reicht nicht, CPU und RAM zu prüfen. Kritisch für HA sind:
- I/O-Wait & Latenzen: Wartet die Datenbank auf die Festplatte?
- RAID- & Hardware-Status: Meldet ein Controller
Degradedoder eine PSU einen Fehler? - Replikations-Lags: Wie weit hinkt der passive Datenbank-Knoten hinterher? Ist der Lag zu groß, ist ein Failover eventuell nicht sicher möglich.
- Intelligentes Alerting & Eskalation: Nichts ist schlimmer als „Alert Fatigue“ (Abstumpfung durch zu viele Mails). Ein gutes System filtert:
- Warning: Festplatte zu 80 % voll → Ticket ins System, keine nächtliche Störung.
- Critical: Cluster-Service gestoppt → Sofortige Benachrichtigung via PagerDuty, OpsGenie oder SMS an den Bereitschaftsdienst.
- Automatisierte Heilung: Skripte (Event Handler), die bei bekannten Fehlermustern (z. B. ein abgestürzter Apache-Prozess) den Dienst automatisch neu starten, bevor überhaupt ein Mensch eingreifen muss.
- Proaktive Wartung & Patch-Management: Die höchste Verfügbarkeit nützt nichts, wenn Sicherheitslücken das System angreifbar machen. HA-Architekturen ermöglichen dir das Patchen ohne Downtime durch Rolling Updates:
- Du versetzt Knoten A in den Wartungsmodus (Drain), verschiebst alle Workloads auf Knoten B, patchst Knoten A und startest ihn neu. Anschließend wiederholst du das Spiel umgekehrt.
- Tipp: Teste Updates immer zuerst in einer Staging-Umgebung, die identisch zur Produktion aufgebaut ist, um Inkompatibilitäten im Cluster-Verbund auszuschließen.
Containerisierung und Cloud-Lösungen
Container-Technologien wie Docker und Orchestrierungstools wie Kubernetes (K8s) haben das Konzept von High Availability grundlegend verändert. Während man früher Server wie „Haustiere“ pflegte, behandelt man sie in modernen Cloud-Native-Umgebungen wie „Nutzvieh“ (Cattle): Fällt eine Instanz aus, wird sie nicht repariert, sondern ersetzt.
Kubernetes als HA-Motor: K8s bietet von Haus aus leistungsstarke Mechanismen zur Selbstheilung (Self-Healing).
- Pod-Level: Stürzt ein Container innerhalb eines Pods ab, startet der Kubelet-Dienst ihn sofort neu.
- Node-Level: Fällt ein ganzer Worker-Node aus (z. B. durch Hardwaredefekt), erkennt der K8s Controller Manager dies, markiert den Node als „NotReady“ und der Scheduler plant die betroffenen Pods automatisch auf gesunden Nodes neu (Rescheduling).
- Architektur-Tipp: Für echte Hochverfügbarkeit muss auch die Control Plane (Master Nodes) redundant ausgelegt sein (üblicherweise 3 Knoten), und die Worker Nodes sollten über verschiedene Brandabschnitte oder Zonen verteilt sein.
Cloud-HA und Auto-Scaling: In der Public Cloud (AWS, Azure, Google Cloud) verlässt man sich nicht mehr auf einzelne Hardware, sondern nutzt Availability Zones (AZs). Eine AZ ist ein isoliertes Rechenzentrum innerhalb einer Region.
- Multi-AZ Deployment: Deine Anwendung läuft parallel in Zone A und Zone B. Fällt Zone A (z. B. durch Stromausfall) komplett aus, leitet der Load Balancer den Traffic nahtlos nach Zone B.
- Auto-Scaling Groups: Diese dienen nicht nur der Lastbewältigung. Sie sind ein essentieller HA-Baustein. Eine „Minimum Health Check“-Regel sorgt dafür, dass kranke Instanzen automatisch terminiert und durch frische ersetzt werden, ohne dass du nachts aufstehen musst.
Hybride Ansätze: Viele Unternehmen nutzen eine Hybrid-Cloud, um sensible Daten On-Premises zu halten, während die Stateless Frontends in der Cloud skalieren. Hier wird die redundante Anbindung (z. B. VPN im Failover mit Direct Connect/ExpressRoute) zum kritischen Pfad.
Disaster Recovery und Geo-Redundanz
Während High Availability dich vor dem Ausfall einzelner Komponenten schützt, ist Disaster Recovery (DR) deine Lebensversicherung gegen den Totalverlust eines Standorts (z. B. durch Brand, Hochwasser, Cyberangriff oder großflächigen Stromausfall). Hierarchisch steht DR über HA und erfordert oft das Ausrufen des Notfalls.
Zentral für deine Strategie sind zwei Kennzahlen:
- RPO (Recovery Point Objective): Wie viele Daten darfst du maximal verlieren? (z. B. „Datenstand von vor 15 Minuten“).
- RTO (Recovery Time Objective): Wie lange darf das System stillstehen, bis es am Zweitstandort läuft? (z. B. „Wiederherstellung binnen 4 Stunden“).
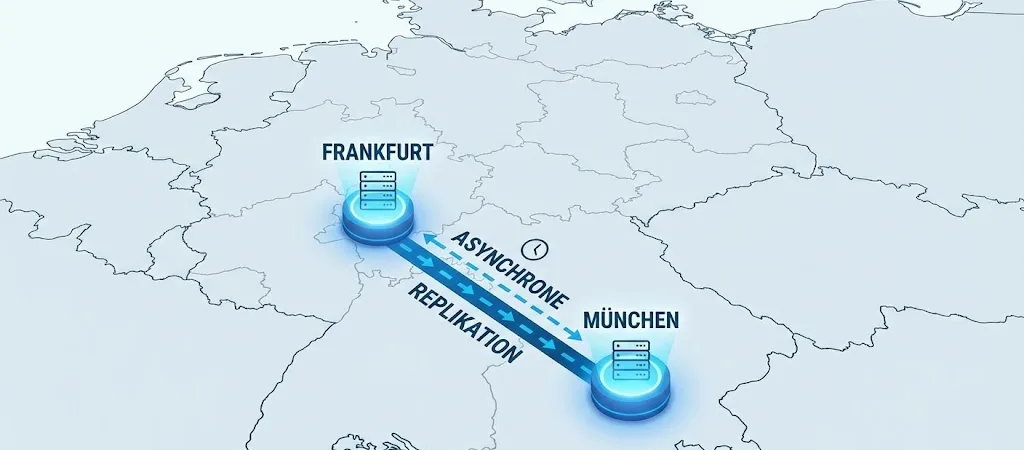
Geo-Redundanz und Replikationsarten: Um echte Geo-Redundanz zu erreichen, sollten Rechenzentren weit genug voneinander entfernt sein (oft >100 km), um nicht von derselben Katastrophe betroffen zu sein. Die Entfernung diktiert die Technik:
- Synchrone Replikation (Campus-Cluster): Daten werden gleichzeitig an Standort A und B geschrieben. Der Schreibvorgang gilt erst als abgeschlossen, wenn beide Bestätigungen vorliegen.
- Vorteil: RPO = 0 (Kein Datenverlust).
- Nachteil: Erfordert extrem geringe Latenz (Dark Fiber), da sonst die Performance der Anwendung leidet. Meist nur bis ca. 10–50 km Entfernung praktikabel.
- Asynchrone Replikation (Geo-Cluster): Daten werden erst lokal geschrieben und dann im Hintergrund an den entfernten Standort übertragen.
- Vorteil: Funktioniert über beliebige Distanzen ohne Performance-Einbußen.
- Nachteil: RPO > 0. Im Katastrophenfall fehlen die Daten der letzten Sekunden oder Minuten, die noch „im Kabel“ waren.
Cloud-Backup als DR-Strategie: Nicht jedes Unternehmen kann sich ein zweites physisches Rechenzentrum leisten. Hier bietet die Cloud attraktive Modelle:
- Cold Standby (Backup & Restore): Daten liegen als Backup in der Cloud (z. B. S3 / Blob Storage). Im Ernstfall werden VMs erst dann hochgefahren und die Daten eingespielt. Günstig, aber hohe RTO.
- Pilot Light: Datenbanken laufen synchronisiert auf kleiner Flamme in der Cloud, Applikationsserver sind aus. Im Notfall werden die App-Server gestartet und die Datenbank hochskaliert. Ein guter Kompromiss aus Kosten und Geschwindigkeit.
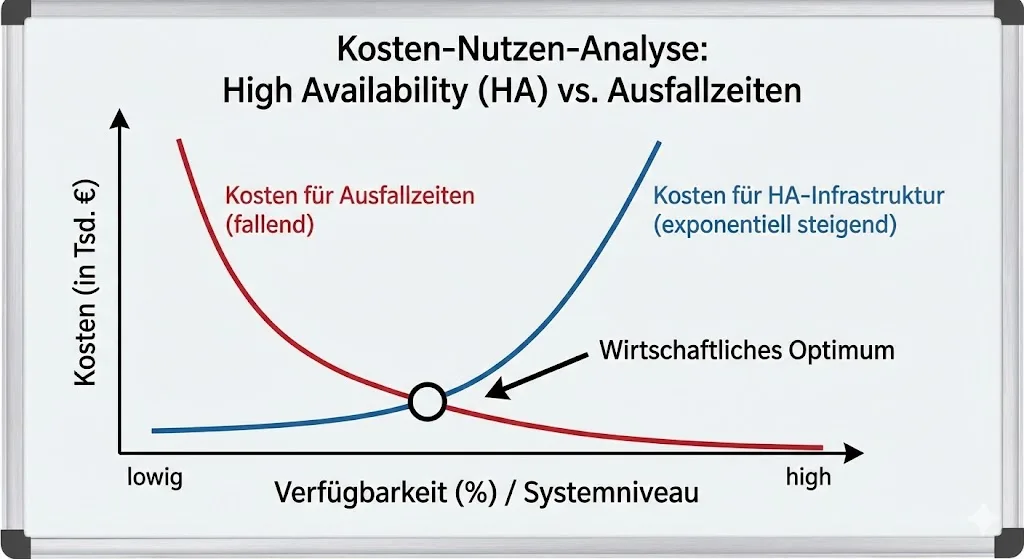
Kosten-Nutzen-Abwägung: Kurve der Sicherheit
Ein System mit 100 % Verfügbarkeit ist ein theoretisches Konstrukt – in der Praxis ist es technisch unmöglich und wirtschaftlich unsinnig. Je näher du den „fünf Neunen“ (99,999 %) kommst, desto exponentieller steigen die Kosten für Hardware, Lizenzen und Personal.
Als Administrator oder Architekt musst du daher oft als Berater für die Geschäftsführung agieren. Die zentrale Frage lautet nicht „Was ist technisch machbar?“, sondern „Was kostet uns der Ausfall?“. Hier hilft eine Business Impact Analysis (BIA).
- Szenario A: Der interne Fileserver fällt für 2 Stunden aus. Ärgerlich, aber die Belegschaft kann lokal weiterarbeiten oder Kaffeepause machen. -> Kostenrisiko: Gering. Ein einfaches RAID und ein tägliches Backup reichen (SLA ~99 %).
- Szenario B: Der Webshop eines E-Commerce-Riesen steht am Black Friday für 2 Stunden still. -> Kostenrisiko: Extrem hoch (Umsatzverlust + Image-Schaden). Hier lohnt sich ein georedundantes Active-Active-Cluster (SLA 99,99 %).
Die Daumenregel: Die Investition in High Availability (HA) und Disaster Recovery (DR) darf nie die potenziellen Kosten eines Ausfalls übersteigen. Oft reicht es, wenn du für geschäftskritische Kerndienste („Tier 1“) maximale Redundanz aufbaust, während Test- oder Archivsysteme („Tier 3“) auch mal einen Tag offline sein dürfen.
Team und Organisation: Faktor Mensch
Selbst die teuerste Hardware ist nutzlos, wenn im Ernstfall Panik ausbricht. Ein hochverfügbares System wird nicht nur durch Technik, sondern vor allem durch Prozesse am Leben gehalten. Die häufigste Ursache für Downtime ist heute nicht mehr der Hardware-Defekt, sondern der menschliche Fehler (Misconfiguration).
Zu einem reifen HA-Konzept gehören daher zwingend:
- Runbooks & Dokumentation: Wissen darf nicht nur in deinem Kopf existieren. Erstelle „Notfall-Runbooks“, die Schritt für Schritt erklären, was bei einem Ausfall von Komponente X zu tun ist. Diese müssen so geschrieben sein, dass auch ein Kollege aus der Rufbereitschaft, der das System nicht gebaut hat, sie nachts um 3 Uhr verstehen kann.
- Regelmäßige „Fire Drills“ & Chaos Engineering: Warte nicht auf den Ernstfall. Teste den Failover!
- Basic: Ziehe im Wartungsfenster das Netzwerkkabel am primären Knoten. Schwenkt die IP um?
- Advanced: Nutze Methoden des „Chaos Engineering“ (wie den Netflix Chaos Monkey), um im laufenden Betrieb zufällig Störungen zu injizieren und die Resilienz deiner Architektur zu härten.
- Post-Mortems: Wenn es geknallt hat, ist die Schuldfrage irrelevant. Führe „Blameless Post-Mortems“ durch. Analysiere den Vorfall technisch (Root Cause Analysis), um zu verstehen, warum der Failover nicht funktioniert hat oder warum das Monitoring nicht alarmiert hat, und verbessere das System für die Zukunft.
- Schulungen: Technologien ändern sich. Wer einen Kubernetes-Cluster betreibt, braucht anderes Wissen als für einen Windows Failover Cluster. Sorge dafür, dass dein Team fit in den eingesetzten Technologien ist.

Fazit
High Availability ist kein Produkt, das du kaufst und ins Rack schraubst. Es ist eine Architektur-Philosophie und ein fortlaufender Prozess. Durch den intelligenten Einsatz von Redundanz (kein Single Point of Failure), Cluster-Technologien (Pacemaker, K8s) und sauberen Failover-Mechanismen (STONITH, Quorum) kannst du Ausfallzeiten drastisch minimieren.
Doch vergiss nie: Die Technik ist nur das Werkzeug. Echte Verfügbarkeit entsteht durch saubere Planung, ständiges Monitoring und ein Team, das den Notfall geübt hat. Geo-Redundanz und Cloud-Lösungen sind dabei mächtige Erweiterungen, um auch gegen Katastrophen gewappnet zu sein.
Deine HA-Checkliste für den Start:
- [ ] SPOF-Analyse: Gibt es Komponenten (Router, Netzteil, Switch), deren Ausfall alles lahmlegt?
- [ ] Redundanz: Ist N+1 überall gewährleistet (Strom, Kühlung, Compute)?
- [ ] Monitoring: Werden nicht nur „Pings“, sondern auch Applikations-Health und Plattenplatz überwacht?
- [ ] Backups: Funktionieren die Backups UND (viel wichtiger) wurden die Restores getestet?
- [ ] Failover-Test: Wann hast du das letzte Mal den Stecker gezogen, um zu sehen, ob der Standby-Server wirklich übernimmt?
- [ ] Doku: Gibt es ein aktuelles Notfall-Handbuch?
Je mehr Haken du hier setzen kannst, desto ruhiger wirst du schlafen – auch wenn der Pager mal schweigt.
weitere Links
| BSI IT-Grundschutz – Standards für Notfallmanagement und Verfügbarkeit | https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Standards-und-Zertifizierung/IT-Grundschutz/it-grundschutz_node.html |
| ClusterLabs – Die zentrale Anlaufstelle für Linux High Availability (Pacemaker/Corosync) | https://clusterlabs.org/ |
| Kubernetes Dokumentation – Konzepte zu Cluster-Architektur und Self-Healing | https://kubernetes.io/de/docs/concepts/architecture/ |
| Atlassian Incident Management – Erklärung zu SLAs und Zeitmetriken (RPO/RTO) | https://www.atlassian.com/de/incident-management/kpis/sla |
| Prometheus Monitoring – Open-Source-Monitoring für zuverlässige Metriken | https://prometheus.io/ |

Sei der Erste und starte die Diskussion mit einem hilfreichen Beitrag.
Kommentar hinterlassen
Dein Beitrag wird vor der Veröffentlichung kurz geprüft — fachlich, respektvoll und auf den Punkt ist hier genau richtig.